
Кодировщик (encoder)
Существует, по меньшей мере, два типа кодеров Рида-Соломона: несистематические и систематические
кодировщики.
Вычисление несистематических корректирующих кодов Рида-Соломона осуществляется умножением информационного слова на порожденный полином, в результате чего образуется кодовое слово, полностью отличающееся от исходного информационного слова, а потому для непосредственного употребления категорически непригодное. Для приведения полученных данных в исходный вид мы должны в обязательном порядке выполнить ресурсоемкую операцию декодирования, даже если данные не искажены и не требуют восстановления!
При систематическом кодировании, напротив, исходное информационное слово останется неизменным, а корректирующие коды (часто называемые символами четности) добавляются в его конец, благодаря чему к операции декодирования приходится прибегать лишь в случае действительного разрушения данных. Вычисление несистематических корректирующих кодов Рида-Соломона осуществляется делением
информационного слова на порожденный полином. При этом, все символы информационного слова сдвигаются на n– k байт влево, а на освободившееся место записывается 2t байт остатка (рис. 21.1).
Рис. 21.1. 0x335 Устройство кодового слова
Поскольку, рассмотрение обоих типов кодировщиков заняло бы слишком много места, сосредоточим свое внимание на одних лишь систематических кодерахкодировщиках, как на наиболее популярных.
Рис. 1.1. 0x335 устройство кодового слова
Архитектурно, кодировщик представляет собой совокупность сдвиговых регистров (shift registers), объединенных посредством сумматоров и умножителей, функционирующих по правилам арифметики Галуа. Сдвиговый регистр (иначе называемый регистром сдвига) представляет последовательность ячеек памяти, называемых разрядами, каждый из которых содержит один элемент поля Галуа GF(q). СодержащейсяСодержащийся в разряде символ, покидая этот разряд, поступает"выстреливается" на выходную линию.
Одновременно с этим, разряд фиксирует"засасывает" символ, находящийся на его входной линии. Замещение символов происходит дискретно, в строго определенные промежутки времени, называемые тактами.
При аппаратной реализации сдвигового регистра его элементы могут быть объедены как последовательно, так и параллельно. При последовательном объединении пересылка одного m-разрядного символа потребуетем m -тактов, в то время как при параллельном она осуществляется всего за один такт.
Низкая эффективность программных реализаций кодиеровщиков Рида-Соломона объясняется тем, что разработчик не может осуществлять параллельное объединение элементов сдвигового регистра и вынужден работать с той шириной разрядности, которую "навязывает" архитектура данной машины. Однако, создать 4-х элементный 8-битный регистр сдвига параллельного типа на процессорах семейства IA-32 вполне реально.
Примечание
IA-32 (Intel Architecture-32 bit) — общее обозначение 32-разрядной архитектуры процессоров корпорации Intel: i386, i486, Pentium, Pentium Pro, Pentium II и т. п.
Цепи, основанные на регистрах сдвига, обычно называют фильтрами. Блок-схема фильтра, осуществляющего деление полинома на константу, приведена на рис. 21.2. Пусть вас не смущает тот факт, что деление реализуется посредством умножения и сложения. Данный прием базируется на вычислении системы двух рекуррентных равенств с помощью формулы деления полинома на константу посредством умножения и сложения:
rx
rx (1.1)
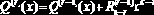
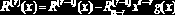
Здесь: Q(r)(x) и R(r)(x) — соответственно, частное и остаток на r-шаге рекурсии. Поскольку сложение и вычисление, выполняемое по модулю два, тождественны друг другу, для реализации делителя нам достаточно иметь всего два устройства — устройство сложения и устройство умножения, а без устройства вычитания можно обойтись.
Рис. 2.2. Устройство простейшего кодировщика Рида-Соломона
После n-сдвигов на выходе регистра появляется частное, а в самом регистре окажется остаток, который и представляет собой рассчитанные символы четности (они же — коды Рида-Соломона), а коэффициенты умножения с g0 по g(2t – -1) напрямую соответствуют коэффициентам умножения порожденного полинома.
Рис. 1.2. 0x336 устройство простейшего кодера Рида-Соломона
Простейший пример программной реализации такого фильтра приведен в листинге 2.19ниже. Это законченный кодировщикера Рида-Соломона, вполне пригодный для практического использования. Конечно, при желании его можно было бы и улучшить, но тогда неизбежно пострадала бы наглядность и компактность листинга.
Листинг 21.19. Исходный текст простейшего кодиеровщикаа Рида-Соломона
/*----------------------------------------------------------------------------
*
* кодировщик Рида-Соломона
* ========================
*
* кодируемые данные передаются через массив data[i], где i=0..(k-1),
* а сгенерированные символы четности заносятся в массив b[0]..b[2*t-1].
* Исходные и результирующие данные должны быть представлены в полиномиальной
* форме (т. е. в обычной форме машинного представления данных).
* кодирование производится с использованием сдвигового feedback-регистра,
* заполненного соответствующими элементами массива g[] с порожденным
* полиномом внутри, процедура генерации которого уже обсуждалась в
* предыдущей главе.
* сгенерированное кодовое слово описывается следующей формулой:
* с(x) = data(x)*x^(n-k) + b(x), где ^ означает возведение в степень
*
* на основе исходных текстов
* Simon'а Rockliff'а, от 26.06.1991
* распространяемых по лицензии GNU
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––-*/
encode_rs()
{
int i, j;
int feedback;
// инициализируем поле бит четности нулями
for (i = 0; i < n - k; i++) b[i] = 0;
// обрабатываем все символы
// исходных данных справа налево
for (i = k - 1; i >= 0; i--)
{
// готовим (data[i] + b[n – k –1]) к умножению на g[i]
// т. е.
складываем очередной "захваченный" символ исходных
// данных с младшим символом битов четности (соответствующего
// "регистру" b2t-1, см. рис. 2.2[Y70] ) и переводим его в индексную
// форму, сохраняя результат в регистре feedback
// как мы уже говорили, сумма двух индексов есть произведение
// полиномов
feedback = index_of[data[i] ^ b[n – k - 1]];
// есть еще символы для обработки?
if (feedback != -1)
{
// осуществляем сдвиг цепи bx-регистров
for (j=n-k-1; j>0; j--)
// если текущий коэффициент g – это действительный
// (т.е. ненулевой коэффициент, то
// умножаем feedback на соответствующий g-коэффициент
// и складываем его со следующим элементов цепочки
if (g[j]!=-1) b[j]=b[j-1]^alpha_to[(g[j]+feedback)%n];
else
// если текущий коэффициент g – это нулевой коэффициент,
// выполняем один лишь сдвиг без умножения, перемещая
// символ из одного m-регистра в другой
b[j] = b[j-1];
// закольцовываем выходящий символ в крайний левый b0-регистр
b[0] = alpha_to[(g[0]+feedback)%n];
}
else
{ // деление завершено,
// осуществляем последний сдвиг регистра,
// на выходе регистра будет частое, которое теряется,
// а в самом регистре – искомый остаток
for (j = n-k-1; j>0; j--) b[j] = b[j-1] ; b[0] = 0;
}
}
}